공장 데이터('Defects', 'Temperature' 등)를 포함한 CSV 파일을 읽어와, 품질 분석에 앞서 필수적으로 수행해야 하는 전처리 작업을 진행합니다.
<요구 사항> - CSV 파일 읽기 및 데이터 기본 확인 1. CSV 파일을 읽어 'DataFrame(df)' 을 생성합니다. 2. 데이터셋 미리보기 : 'df'의 상위 5개 행을 출력하세요. 3. 데이터 정보 : 컬럼명, 데이터 타입, 결측치 등 기본 정보를 출력하세요. 4. 기술 통계 : 평균, 표준편차, 최소/최대값 등 기술 통계를 출력하세요. 5. 결측값 개수 : 각 열별로 결측값이 몇 개인지 출력하세요. 6. 중복 행이 몇 개인지 출력하세요
# 1) CSV 파일을 읽어 DataFrame 생성 (Data는 manu) df = pd.read_csv('manufacturing_data_400.csv')
# 2) df의 상위 5개 행을 확인하고 출력 print(df.head())
# 3) df의 기본 정보(컬럼명, 데이터 타입, etc.) 출력 print(df.info())
# 4) df의 기술 통계(평균, 표준편차 등) 출력 print(df.describe())
# 5) df의 컬럼별 결측값 개수 출력 print(df.isna().sum())
# 6) df의 중복 행이 몇 개인지 출력 print(df.duplicated().sum())
🔩Level.1-2 결측치 처리
<요구사항> 1. 'Defects' 열에 이상치로 추정되는 '9999'라는 값을 발견했습니다. 2. 'Temperature' 열에 존재하는 결측치(또는 NaN)을 'Temperature 열의 평균값'으로 대체
# 2) Temperature 열 결측치를 해당 열의 평균값으로 대체 df['Temperature'] = df['Temperature'].fillna(df['Temperature'].mean())
mask()를 사용하지 않고 replace()를 이용해서 코드를 작성하고 싶었는데
df['Defects'] = df['Defects'].replace(df['Defects'] >= 9999, pd.NA)를 그대로 위 코드 대신 넣게 되면 오류가 발생함. 이유? : replace 함수가 조건문을 직접적으로 처리하지 않고, replace 함수는 값이 정확히 일치하는 항목을 찾아 대체하는 방식으로 작동 즉, replace 함수는 특정 값을 다른 값으로 대체하는 데 사용되지만, 조건을 기준으로 변경하려면 다른 접근 방식이 필요함.
주의!! 1-2에서 9999값만 pd.NA로 바꿔주면 뒤에 문제에서 다 오류남! 9999보다 큰 값은 모두 pd.NA로 변경해주어야함! 따라서 replace말고 mask 를 사용해야함.
🔩Level. 1-3 이상치 식별 (IQR)
<요구사항> 1. 사분위수 계산 -'Defects' 열의 25% 사분위수(Q1)와 75% 사분위수(Q3)를 구합니다. - IQR(Interquartile Range) = Q3 - Q1** 을 계산합니다. - Lower Bound = Q1 - (1.5 × IQR), Upper Bound = Q3 + (1.5 × IQR)을 계산합니다. 2. 이상치 데이터 추출 - 'Defects' 값이 Lower Bound 미만이거나 Upper Bound 초과인 경우를 이상치로 간주하고, 이상치 데이터를 추출합니다. - 이상치에 해당하는 행이 몇 개인지, 그리고 그 샘플을 출력하세요. 3. 잠깐! IQR이란? : IQR(Interquartile Range)은 데이터의 25% 지점인 Q1과 75% 지점인 Q3의 차이를 의미합니다. 전체 데이터의 중간 50%가 어떻게 분포되어 있는지 파악할 수 있습니다. 이상치(Outlier)를 판단에 주로 활용되는데, 일반적으로 Q1에서 1.5×IQR을 뺀 값보다 작거나, Q3에 1.5×IQR을 더한 값보다 큰 데이터를 이상치로 간주합니다.
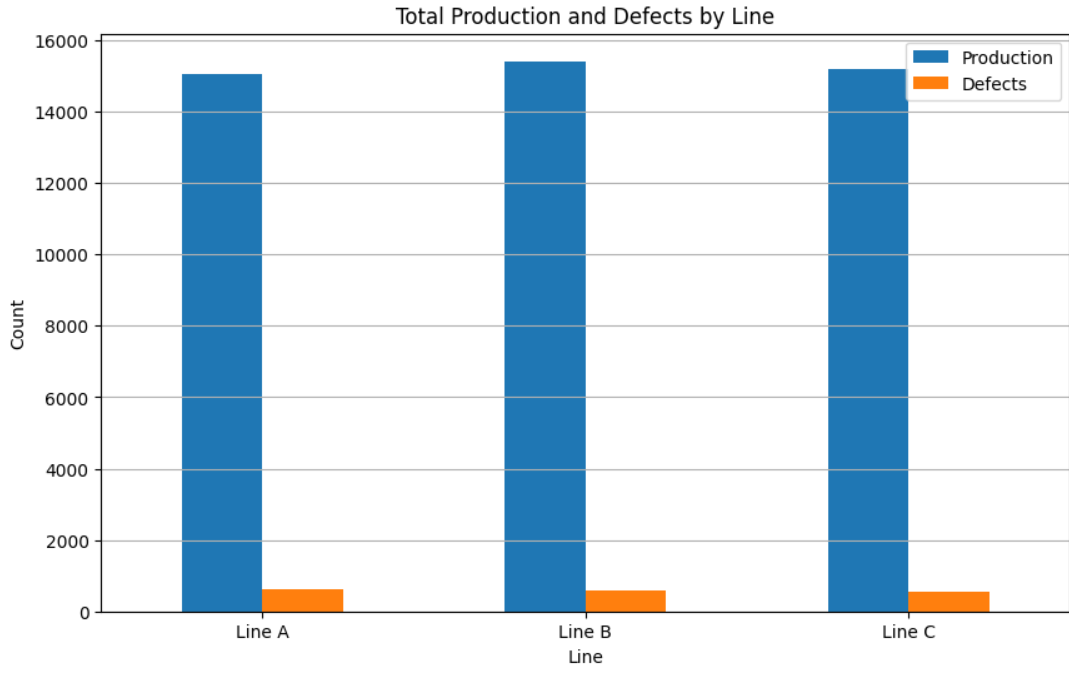
<문제 설명> 공장 내에는 A, B, C 등 여러 생산 라인(Line)이 존재하며, 각 라인마다 하루 생산량(Production)과 불량(Defects) 데이터가 기록됩니다. 라인별로 이러한 데이터를 그룹화하여 생산량과 불량 수치를 파악하고, 막대 그래프(Bar Chart)로 시각화하여 비교하려고 합니다.
<요구사항> 1. 라인별 그룹화 - 주어진 데이터에서 라인(Line) 을 기준으로 그룹화하세요. - 각 라인별 생산량(Production) 과 불량(Defects) 의 총합(합계)을 구하세요. 2. Bar Chart 작성 - X축에는 라인(Line) 을 표시합니다. - Y축에는 생산량(Production) 과 불량(Defects) 의 합계를 나타냅니다. - 각 라인별로 두 가지 막대(Production/Defects)를 나란히 배치하여 시각적인 비교가 가능하도록 합니다. 3. 그래프 꾸미기 - 그래프의 제목(title) 을 적절히 설정하세요. - X축 라벨(xlabel)과 Y축 라벨(ylabel)을 알맞게 설정합니다. - 범례(legend)를 추가하여 Production 와 Defects를 명확하게 구분하세요. - X축에 라인(A, B, C) 이름이 정확히 표시되도록 하세요 (필요에 따라 'plt.xticks' 등을 사용) - Y축에 대한 격자(grid)를 추가하여 막대의 높이를 쉽게 확인할 수 있도록 합니다.
#코드를 작성하세요 import pandas as pd import matplotlib.pyplot as plt
#빈칸을 작성하세요 plt.title('Total Production and Defects by Line') plt.xlabel('Line') plt.ylabel('Count') plt.xticks(rotation=0) plt.legend(['Production', 'Defects']) plt.grid(axis='y') plt.show()
2-1 결과 그래프
그래프 막대 색깔을 따로 지정하지 않으면, 파란색-> 주황색-> 초록색 순서로 자동 배정되는 듯!!
🔩 Level.2-2: Pie Chart: 라인별 Production 비중
<문제 설명> 공장 내 여러 생산 라인(A, B, C)이 전체 생산량('Production')에서 각각 어느 정도의 비중을 차지하는지 파악하기 위해, 파이 차트(Pie Chart)를 작성하려고 합니다.
<요구사항> 1.Pie Chart 작성 - 파이 차트를 사용하여 각 라인의 'Production' 비중을 시각화하세요. - 각 파이 조각에 라인 이름과 퍼센트(%)를 표시하기 위해 'autopct='%1.1f%%'' 옵션을 사용하세요. - 파이 차트의 색상을 라인별로 다르게 지정하여 구분이 용이하도록 합니다. 2.그래프 꾸미기 - 그래프의 제목(title)을 적절히 설정하세요 (예: "라인별 Production 비중").
- 불필요한 축 라벨(예: 축 눈금)을 제거하여 파이 차트가 깔끔하게 보이도록 합니다. - 그래프의 색상을 명확히 구분할 수 있도록 설정하세요.
plt.title('Percentage of Production by Line') plt.show()
2-2 결과 그래프(왼쪽이 정답!)
plt.pie(pie_data, labels=pie_data.index, autopct='%1.1f%%',startangle=90)에서 labels=pie를 없애고, startangle=90을 안해주면 , 오른쪽 그래프처럼 텍스트도 없어지고 돌아간 원 모양이 나오게 됨!
🔩 Level.2-3: 혼합 Line Chart: 일자별 Production & Defects
<문제 설명> 공장에서는 매일 다양한 제품을 생산하고, 그 과정에서 발생하는 불량 수량 역시 기록합니다. 일자별 생산량(Production)과 불량 수량(Defects)을 시각적으로 비교하여 불량률 추이와 생산 변동성을 파악하려고 합니다. 이에 따라, 주어진 데이터를 날짜별로 집계하고 선 그래프(Line Chart)로 나타내는 작업을 수행해야 합니다.
<요구사항> 1. 날짜별 집계 - 주어진 데이터에서 “일자(Date)”, “생산량(Production)”, “불량(Defects)”을 날짜별로 그룹화하여 총합(또는 평균)으로 집계하세요. 2. Line Chart 작성 - X축에는 날짜(Date)를, Y축에는 “생산량(Production)”과 “불량(Defects)” 수치를 배치합니다. - 날짜별 “Production”을 나타내는 선과 “Defects”를 나타내는 선을 **같은 그래프**에 그립니다. 3.그래프 꾸미기 - 그래프의 제목(title)을 적절히 설정하세요. - X축 라벨(xlabel)과 Y축 라벨(ylabel)을 설정합니다. - 범례(legend)를 통해 두 선이 어떤 값(Production/Defects)인지 명확히 구분되도록 합니다. - 그래프에 격자(grid)를 추가하여 가독성을 높이세요. 4.복합 그래프 그리는 법? - 라인 그래프 작성 코드에 추가하면 됩니다!
plt.title('Daily Trends:Production and Defects') plt.xlabel('Data') plt.ylabel('Count') plt.legend(loc='center left') plt.grid() plt.show()
2-3 결과 그래프
plt.legend() 에서 괄호 내에 'loc=center left'를 적어서 범례의 위치를 조정할 수 있다! 그냥 'left'만 적으면 오류발생함.
참고) loc='center left': 범례를 왼쪽 중앙에 배치 loc='upper left': 범례를 왼쪽 위에 배치 loc='lower left': 범례를 왼쪽 아래에 배치 loc='upper right': 범례를 오른쪽 위에 배치 loc='lower right': 범례를 오른쪽 아래에 배치 loc='center': 범례를 중앙에 배치
LEVEL3
🔩Level. 3-1: Production distribution
<문제 설명> 1. Histogram : 'production'열을 사용하여 Production distribution를 확인합니다. 2. Pie Chart : 결함률(`defect_rate`)데이터를 어느 정도의 비중을 차지하는지 파악하기 위해, 파이 차트(Pie Chart)를 생성합니다. 3. 한 걸음 더: - 각 문제에는 분석가의 해석을 작성하는 공간이 있습니다. - 전처리와 시각화를 바탕으로 각자의 결론과 인사이트를 자유롭게 적어주세요!
<요구사항> - 'data_cleaned'라는 'DataFrame'에서 'production' 열을 사용하여 히스토그램을 작성하세요. - 막대(bin)의 개수(bins)는 10으로, 막대 테두리 색(edgecolor)은 'k'(검정색), 투명도(alpha)는 0.7로 지정하세요. - 그래프 제목(title)은 "Production Distribution"으로 하고, - x축 라벨: 'Production' - y축 라벨: 'Frequency'를 각각 설정하세요. - 히스토그램이 완성되면, 생산량이 어떤 구간대에 집중되어 있는지 간단히 해석해 보세요. (예: “생산량이 대체로 20~40 구간에 몰려 있다.” 등)
# 라이브러리 불러오기 import matplotlib.pyplot as plt import pandas as pd
# 서브플롯 레이아웃 설정 (2행 3열의 첫 번째 위치) data_cleaned = pd.read_csv('data_with_duplicates.csv')
위 코드를 작성해주지 않으면, 1000이하의 data값(defect_rate=NaN)들이 존재하기 때문에, 중간그래프처럼 1000이하의 Prodcution값이 생긴다. 또한, 동일한 값들 즉, 중복값들에 의해서 Frequency의 값도 40, 10의 값을 가진다.
따라서 올바른 그래프를 도출하기 위해서, NaN 값의 행을 제거하는 코드와 중복값의 행을 제거하는 코드가 필요하다.
* 제일 오른쪽 그래프는 NaN값의 행은 제거했지만, 중복값을 제거하지 않았을 때 나타나는 그래프의 형태이다!
🔩Level.3-2: Defect Rate Category 파이 차트 시각화
<요구사항> 1. 결함률('defect_rate') 데이터를 구간(binning) 별로 범주화(Category)하십시오. - 구간 구분은 '[0, 0.015, 0.02, 0.025]'로 설정하고, 각 구간에 대한 범주 라벨(labels)은 '['Low (<= 0.015)', 'Medium (0.015-0.02)', 'High (> 0.02)']`-'로 지정하세요. - 'pandas.cut()'함수를 활용하여, 'data_cleaned['defect_rate']'를 'defect_rate_category'라는 새로운 컬럼으로 생성하세요. 1. 범주화된 결함률('defect_rate_category')의 각 범주별 빈도수를 계산하세요. ('value_counts()'활용) 2. 파이 차트(Pie Chart)를 그릴 때, 아래 조건을 만족하세요. - 차트 크기: 'figsize=(8, 6)' - 파이 섹션의 색상: '['#66b3ff', '#99ff99', '#ffcc99']' - 퍼센트 표시: 'autopct='%1.1f%%'' - 시작 각도: 'startangle=140' - 차트 제목: 'Defect Rate Categories' 3. 파이 차트를 통해, 결함률이 어느 구간에 많이 분포되어 있는지 확인하고, 그에 대한 짧은 해석을 기술하세요. - 예: “대부분의 결함률이 'Low (<= 0.015)' 구간에 분포한다.”, “약 20%는 'High (> 0.02)' 범주에 해당한다.” 등
# 라이브러리 불러오기 import matplotlib.pyplot as plt import pandas as pd
# 결함률 데이터를 범주화하여 새로운 컬럼 생성 data_cleaned['defect_rate_category'] = pd.cut(data_cleaned['defect_rate'], bins=binning, labels=labels) category_data = data_cleaned['defect_rate_category'].value_counts()
# 파이 차트 생성 plt.figure(figsize=(8, 6)) plt.pie(category_data, labels=labels, colors=['#66b3ff', '#99ff99', '#ffcc99'],autopct='%1.1f%%', startangle=140)
# 차트 제목 설정 plt.title('Defect Rate Categories')
# 차트 표시 plt.show()
# 분석가의 해석 ###Low, Medium, High 3개의 구간 비율이 33.3%로, 특정 구간에 집중되지 않고 균등하게 분포한다.
3-2 결과 그래프
3-2도 data_cleaned(3-1에서 정의)를 사용함.
즉, data_cleaned는 NaN값 행, 중복값 행 제거가 다 되어있는 데이터이기 때문에 추가로 제거 코드를 작성하지 않고 data_cleaned를 사용하면됨!
[개인과제하면서 느낀점]
: 도출되어야하는 그래프가 주어져있어서 거의 그 그래프가 나오도록 코드를 끼워 맞추기하는 느낌이었다.
아직까지 Level 3문제에서 왜 중복값을 제거하는지 모르겠다. 생산량 관련해서 얻어진 데이터를 동일한 값이라고해서 제거해버리면 문제가 되는 것 아닌가? NaN 값의 행을 제거하는 것은 이해되는데 중복값은 무엇을 위해서 제거하는지 이해가 안된다.
누가 이해 좀 시켜줘....
문제가 어떤 그래프를 그리고자 하는지 이해한 후, 코드를 작성할 필요가 있다는 것을 많이 느꼈다.