머신러닝의 이해와 라이브러리 활용 기초(1)
강의 내용 실습
# !pip install scikit-learn
# !pip install numpy
# !pip install pandas
# !pip install matplotlib
# !pip install seaborn
import sklearn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
1. Weight VS. Height
: 몸무게와 키의 상관관계
weights = [87,81,82,92,90,61,86,66,69,69]
heights = [187,174,179,192,188,160,179,168,168,174]
print(len(weights))
print(len(heights)
# 딕셔너리 형태로 데이터 생성
body_df = pd.DataFrame({'height': heights, 'weight': weights})
W1,W0 구하기(1)
#선형 회귀 훈련(적합)
from sklearn.linear_model import LinearRegression
model_lr = LinearRegression()
type(model_lr)
# DataFrame[]: Series(데이터 프레임의 컬럼)
# DaraFream[[]]: DataFrame
x = body_df[['weight']]
y = body_df[['height']]
#데이터 훈련
model_lr.fit(X = x, y = y)
# 가중치(w1)
print(model_lr.coef_)
# 편향(bias,w0)
print(model_lr.intercept_)
출력:
[[0.86251245]]
[106.36527488]
W1,W0 구하기(2)
w1 = model_lr.coef_[0][0]
w0 = model_lr.intercept_[0]
print('y= {}x + {}'.format(w1.round(2),w0.round(2)))
출력: y = 0.86 + 109.37
MES 계산 (1)
# 예측값을 만들기 [pred]
body_df['pred'] = body_df['weight']*w1 + w0
body_df.head(3)
# 에러값 계산(실제값-예측값) [error]
body_df['error'] = body_df['height']-body_df['pred']
body_df.head(3)
body_df['error^2'] = body_df['error']**2
body_df.head(3)
#MES 계산 답: 10
body_df['error^2'].sum()/len(body_df)
출력: 10.15293904537609
MES 계산 (2) + r2_score
from sklearn.metrics import mean_squared_error, r2_score
# 평가함수는 공통적으로 정답(실제 true), 예측값(pred)
y_true = body_df['height']
y_pred = body_df['pred']
mean_squared_error(y_true,y_pred)
출력: 10.152939045376309
r2_score(y_true,y_pred)
출력:0.8899887415172141
MES 계산 (3)
# 예측값 알아내는 또다른 코드 predict()
y_pred2 = model_lr.predict(body_df[['weight']])
y_pred2
mean_squared_error(y_true,y_pred2)
출력:10.152939045376309
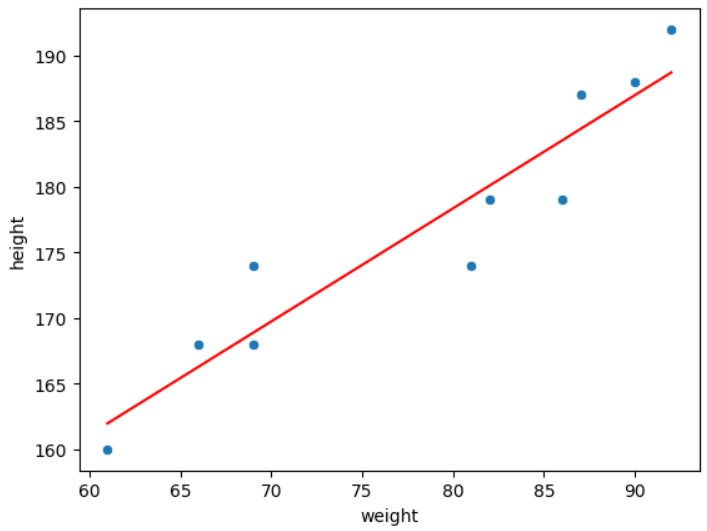
시각화(산점도, 선 그래프)
sns.scatterplot(data = body_df, x = 'weight', y = 'height')
sns.lineplot(data = body_df, x = 'weight', y = 'pred', color = 'red')
2. Total_bill VS. Tip
: 전체 금액과 팁의 상관관계
tips_df = sns.load_dataset('tips')
W1, W0 구하기 (1)
model_lr2 = LinearRegression()
x = tips_df[['total_bill']]
y = tips_df[['tip']]
model_lr2.fit(x,y)
# y(tip) = w1*x(totall_bill) + w0
w1_tip = model_lr2.coef_[0][0]
w0_tip = model_lr2.intercept_[0]
print('y = {}x + {}'.format(w1_tip.round(2),w0_tip.round(2)))
출력: y = 0.11x + 0.92
MES 계산 (1) + r2_score
# 예측값 생성
y_true_tip = tips_df['tip']
y_pred_tip = model_lr2.predict(tips_df[['total_bill']])
#y_pred_tip도 tips_df에 컬럼으로 넣어주기
tips_df['pred'] = y_pred_tip
mean_squared_error(y_true_tip, y_pred_tip)
출력: 1.036019442011377
r2_score(y_true_tip, y_pred_tip)
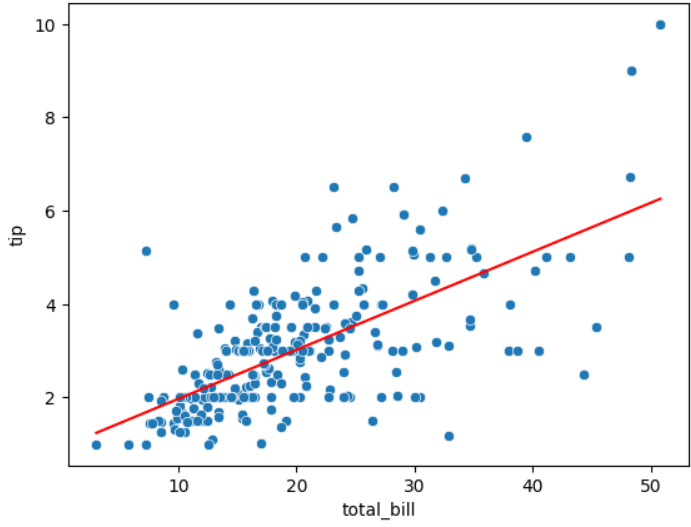
시각화(산점도, 선 그래프)
sns.scatterplot(data = tips_df, x= tips_df['total_bill'], y=tips_df['tip'])
sns.lineplot(data = tips_df, x = 'total_bill', y = 'pred', color = 'red')
'QCQA_1기' 카테고리의 다른 글
| TIL_6W2D_머신러닝 기초(2) (0) | 2025.01.21 |
|---|---|
| TIL_5W5D_통계학 기초 정리(3-6주차) (0) | 2025.01.20 |
| TIL_5W3D~4D_통계학 기초 정리(1-2주차) (0) | 2025.01.17 |
| TIL_5W2D_첫번째 프로젝트 시작과 끝 (0) | 2025.01.15 |
| TIL_5W1D_지금까지 푼 데일리 루틴 정리(알고리즘_프로그래머스) (0) | 2025.01.13 |