평균(Mean): 평균은 모든 데이터를 더한 후, 데이터의 개수로 나누어 계산 ex) 다섯 명의 학생이 받은 시험 점수가 70, 80, 90, 100, 60이라면, 평균은 (70 + 80 + 90 + 100 + 60) / 5 = 80
중앙값(Median): 중앙값은 데이터 셋을 크기 순서대로 정렬했을 때 중앙에 위치한 값 ex) 시험 점수가 60, 70, 80, 90, 100일 때, 중앙값은 80 / 짝수 개수라면, 중앙에 있는 두 값의 평균을 중앙값
분산(Variance): 데이터 값들이 평균으로부터 얼마나 떨어져 있는지를 나타내는 척도, 데이터의 흩어짐 정도 분산이 크면 데이터가 넓게 퍼져 있고, 작으면 데이터가 평균에 가깝게 모여 있음 각 데이터 값에서 평균을 뺀 값을 제곱한 후, 이를 모두 더하고 데이터의 개수로 나누는 것 ex) 네 명의 학생이 받은 시험 점수가 70, 80, 90, 100이라면, 평균은 (70 + 80 + 90 + 100) / 4 = 85, 분산 = (225 + 25 + 25 + 225) / 4 = 125
표준편차(Standard Deviation): 데이터 값들이 평균에서 얼마나 떨어져 있는지를 나타내는 통계적 척도, 분산의 제곱근 표준편차가 크면 데이터가 평균으로부터 더 넓게 퍼져 있음을 의미 ex) 분산이 125라면, 표준편차는 분산에 루트를 씌워 약 11.18
[추론통계]
표본 데이터를 통해 모집단의 특성을 추정하고 가설을 검정하는 통계방법
주로 신뢰구간, 가설검정 등을 사용
데이터의 일부를 가지고 데이터의 전체를 추정
신뢰구간(Confidence Interval): 모집단의 평균이 특정 범위 내에 있을 것이라는 확률 일반적으로 95% 신뢰구간이 사용되며, 이는 모집단 평균이 95%의 확률로 이 구간 내에 있음을 의미 ex) 어떤 설문조사에서 평균 만족도가 75점이고, 신뢰구간이 70점에서 80점이라면, 우리는 95% 확률로 실제 평균 만족도가 이 범위 내에 있다
가설검정(Hypothesis Testing): 모집단에 대한 가설을 검증하기 위해 사용 귀무가설(H0)-검증하고자 하는 가설이 틀렸음을 나타내는 기본가설(변화가 없다, 효과가 없다)이고, 대립가설(H1)-그 반대 가설로 주장하는 바를 나타냄(변화가 있다, 효과가 있다) ex) , 새로운 교육 프로그램이 학생들의 성적에 영향을 미치는지 알고 싶다면, 귀무가설은 "프로그램이 성적에 영향을 미치지 않는다"이고, 대립가설은 "프로그램이 성적에 영향을 미친다"
3. 다양한 분석 방법
1) 위치추정
평균, 중앙값이 대표적인 위치 추정 방법!
# 데이터 분석에서 자주 사용되는 라이브러리 import pandas as pd # 다양한 계산을 빠르게 수행하게 돕는 라이브러리 import numpy as np # 시각화 라이브러리 import matplotlib.pyplot as plt # 시각화 라이브러리2 import seaborn as sns
# 이 data는 아래에서도 계속 사용 data = [85, 90, 78, 92, 88, 76, 95, 89, 84, 91] mean = np.mean(data) median = np.median(data)
# 스튜던트 t 분포 곡선 추가 x = np.linspace(-4, 4, 100) p = stats.t.pdf(x, df=10) plt.plot(x, p, 'k', linewidth=2) plt.title('student t distribution histogram') plt.show()
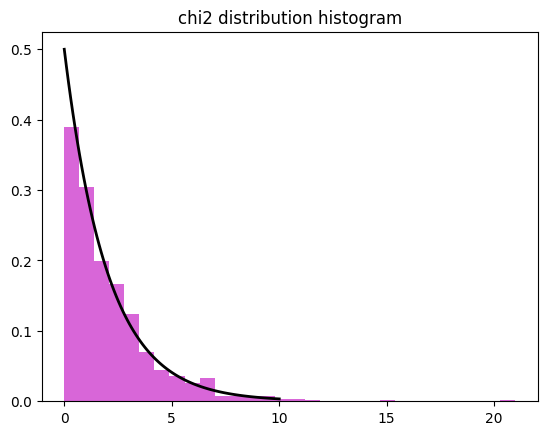
6. 카이제곱분포
범주형 데이터의 독립성 검정이나 적합도 검정에 사용
자유도에 따라 모양이 달라짐, 상관관계나 인과관계를 판별하고자 하는 원인의 독립변수가 완벽하게 서로 다른 질적 자료일때 활
# 카이제곱분포 생성 chi2_dist = np.random.chisquare(df=2, size=1000)